
章
目
录
内存
JMM
内存模型
Java 内存模型是 Java Memory Model(JMM),本身是一种抽象的概念,实际上并不存在,描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式
JMM 作用:
- 屏蔽各种硬件和操作系统的内存访问差异,实现让 Java 程序在各种平台下都能达到一致的内存访问效果
- 规定了线程和内存之间的一些关系
根据 JMM 的设计,系统存在一个主内存(Main Memory),Java 中所有变量都存储在主存中,对于所有线程都是共享的;每条线程都有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作都是先对变量进行拷贝,然后在工作内存中进行,不能直接操作主内存中的变量;线程之间无法相互直接访问,线程间的通信(传递)必须通过主内存来完成
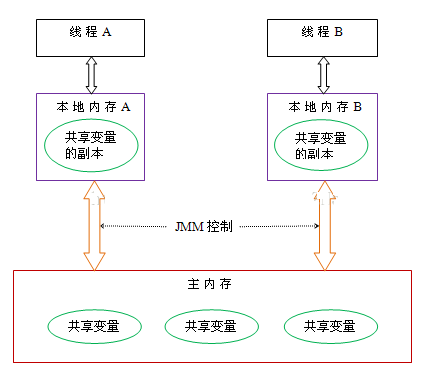
主内存和工作内存:
- 主内存:计算机的内存,也就是经常提到的 8G 内存,16G 内存,存储所有共享变量的值
- 工作内存:存储该线程使用到的共享变量在主内存的的值的副本拷贝
JVM 和 JMM 之间的关系:JMM 中的主内存、工作内存与 JVM 中的 Java 堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来:
- 主内存主要对应于 Java 堆中的对象实例数据部分,而工作内存则对应于虚拟机栈中的部分区域
- 从更低层次上说,主内存直接对应于物理硬件的内存,工作内存对应寄存器和高速缓存
内存交互
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作,每个操作都是原子的
非原子协定:没有被 volatile 修饰的 long、double 外,默认按照两次 32 位的操作
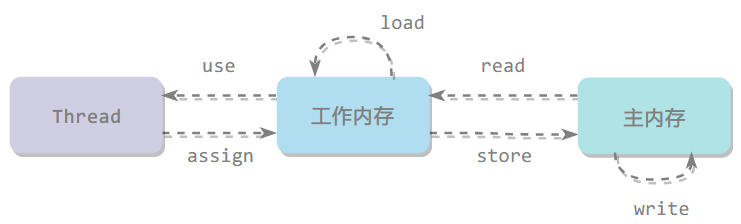
- lock:作用于主内存,将一个变量标识为被一个线程独占状态(对应 monitorenter)
- unclock:作用于主内存,将一个变量从独占状态释放出来,释放后的变量才可以被其他线程锁定(对应 monitorexit)
- read:作用于主内存,把一个变量的值从主内存传输到工作内存中
- load:作用于工作内存,在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
- use:作用于工作内存,把工作内存中一个变量的值传递给执行引擎,每当遇到一个使用到变量的操作时都要使用该指令
- assign:作用于工作内存,把从执行引擎接收到的一个值赋给工作内存的变量
- store:作用于工作内存,把工作内存的一个变量的值传送到主内存中
- write:作用于主内存,在 store 之后执行,把 store 得到的值放入主内存的变量中
参考文章:https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20%E5%B9%B6%E5%8F%91.md
三大特性
可见性
可见性:是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值
存在不可见问题的根本原因是由于缓存的存在,线程持有的是共享变量的副本,无法感知其他线程对于共享变量的更改,导致读取的值不是最新的。但是 final 修饰的变量是不可变的,就算有缓存,也不会存在不可见的问题
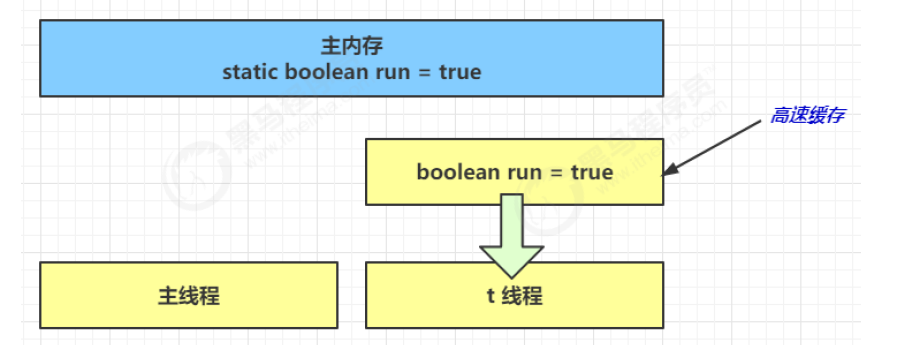
main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:
static boolean run = true; //添加volatile
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
// ....
}
});
t.start();
sleep(1);
run = false; // 线程t不会如预想的停下来
}
原因:
- 初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存
- 因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率
- 1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值
原子性
原子性:不可分割,完整性,也就是说某个线程正在做某个具体业务时,中间不可以被分割,需要具体完成,要么同时成功,要么同时失败,保证指令不会受到线程上下文切换的影响
定义原子操作的使用规则:
- 不允许 read 和 load、store 和 write 操作之一单独出现,必须顺序执行,但是不要求连续
- 不允许一个线程丢弃 assign 操作,必须同步回主存
- 不允许一个线程无原因地(没有发生过任何 assign 操作)把数据从工作内存同步会主内存中
- 一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(assign 或者 load)的变量,即对一个变量实施 use 和 store 操作之前,必须先自行 assign 和 load 操作
- 一个变量在同一时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁,lock 和 unlock 必须成对出现
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量之前需要重新从主存加载
- 如果一个变量事先没有被 lock 操作锁定,则不允许执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量
- 对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(执行 store 和 write 操作)
有序性
有序性:在本线程内观察,所有操作都是有序的;在一个线程观察另一个线程,所有操作都是无序的,无序是因为发生了指令重排序
CPU 的基本工作是执行存储的指令序列,即程序,程序的执行过程实际上是不断地取出指令、分析指令、执行指令的过程,为了提高性能,编译器和处理器会对指令重排,一般分为以下三种:
源代码 -> 编译器优化的重排 -> 指令并行的重排 -> 内存系统的重排 -> 最终执行指令
现代 CPU 支持多级指令流水线,几乎所有的冯•诺伊曼型计算机的 CPU,其工作都可以分为 5 个阶段:取指令、指令译码、执行指令、访存取数和结果写回,可以称之为五级指令流水线。CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(每个线程不同的阶段),本质上流水线技术并不能缩短单条指令的执行时间,但变相地提高了指令地吞吐率
处理器在进行重排序时,必须要考虑指令之间的数据依赖性
- 单线程环境也存在指令重排,由于存在依赖性,最终执行结果和代码顺序的结果一致
- 多线程环境中线程交替执行,由于编译器优化重排,会获取其他线程处在不同阶段的指令同时执行
补充知识:
- 指令周期是取出一条指令并执行这条指令的时间,一般由若干个机器周期组成
- 机器周期也称为 CPU 周期,一条指令的执行过程划分为若干个阶段(如取指、译码、执行等),每一阶段完成一个基本操作,完成一个基本操作所需要的时间称为机器周期
- 振荡周期指周期性信号作周期性重复变化的时间间隔




